Language Learning Bot: Saving LLM Output to a Database
ChatGPT has become so popular in large part because it allows people to express their goals in natural language. Through ChatGPT’s conversational interface, people can explain exactly what they want to understand, create, or explore. Naturally, LLMs have been closely associated with conversations with users. With OpenAI’s API (among many other LLM options), many applications develop interfaces and prompts to facilitate exchanges between users and the LLM. Instead of exposing an LLM directly to users, it can make more sense to incorporate an LLM deeper in an application, working with the system instead of the user. In particular, an application may benefit from saving and reusing content the LLM generates.
The cost of the LLMs can really add up. Long prompts and long output cost more. And that cost depends on what language you are using, too. Yennie Jun wrote an excellent overview comparing token lengths of different languages. For just the last few blogs I wrote, I spent about $3.00 on testing, much of which was spent on trying out prompts in Korean. Imagine an application with thousands of users trying to use those features.
Additionally, external LLMs can take a long time to return a response. The time to get a response can vary widely. Here are some times for chat exchanges:
User: When is the cafe open?
AI: " Sorry, I'm not sure about that. Why don't you ask me about my food menu?"
Completion Time: 1.94 sUser: Where is the store located?
AI: " Sorry, I'm not sure about that. Why don't you ask me about my drink
menu?"
Completion Time: 3.94 sUser: What does revision mean?
AI: {"definition": "Travel means to go to another place", "synonym": "venture",
"antonym": "stay", "example": "I want to travel to Europe one day!"}
Completion Time: 6.38 sThere’s a lot going on - requests are moving back and forth, the LLM is reading in the prompt, it’s doing the calculations to produce output, and any other system actions along the way. Nonetheless, around 6 seconds for every turn in a conversation would get tedious.
Finally, we cannot really trust the output LLMs generate. Depending on our use case, we may want to verify the content before sending it to a user. For example, giving a language learner the wrong definition for a vocab word can have serious implications for that student’s studies, not to mention their confidence.
With these challenges in mind, let’s shift our focus to setting up our LLM and working with a database. As usual, this tutorial will assume that you have an .env file to store your credentials.
The first thing we’ll do is set up a class with everything to make our LLM calls.
from langchain import OpenAI, ConversationChain, LLMChain, PromptTemplate
from langchain.memory import ConversationBufferMemory
from langchain import FewShotPromptTemplate
class LLMBaseClass():
suffix = """
Current conversation:
{history}
User: {input}
AI: """
example_template = """
Example
User: {input}
AI: {output}
"""
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template=example_template
)
def __init__(
self,
prefix,
examples,
suffix=suffix,
example_template=example_template,
example_prompt=example_prompt,
):
self.prefix=prefix
self.suffix=suffix
self.example_template=example_template
self.example_prompt=example_prompt
self.examples=examples
def create_few_shot_prompt_template(self):
return FewShotPromptTemplate(
prefix=self.prefix,
suffix=self.suffix,
examples=self.examples,
example_prompt=self.example_prompt,
input_variables=["history", "input"],
example_separator="\n\n"
)
def call_llm(self, input):
language_bot_chain = LLMChain(
llm=OpenAI(temperature=0),
prompt=self.create_few_shot_prompt_template(),
verbose=True,
memory=ConversationBufferMemory(),
)
output = language_bot_chain.predict(input=input)
return outputTo use our class, we’ll need to provide a prompt and examples. In this article, we’ll revisit the vocabulary bot from earlier. However, instead of writing a response for students, we will ask the LLM to produce a JSON object with information about a vocabulary term.
prefix = "The assistant is helping people to learn the English words that they have trouble with and want to know about. The assistant provides a simple explanation in English to define words, but also provides example words and phrases in English. The assistant must provide it's response in properly formatted JSON. The following examples demonstrate the appropriate type of responses the assistant should provide to answer a user's query."We’ll need to provide JSON objects in our examples. We’re just going to get the definition, a synonym, an antonym, and an example sentence. Usually, JSON looks like {“key”: “value”} . To use JSON in the PromptTemplate for examples, we need to use double brackets {{“key”: “value”}} . The extra brackets escape the first set of brackets.
examples = [
{
"input": "What does travel mean?",
"output": """{{"definition": "Travel means to go to another place", "synonym": "venture", "antonym": "stay", "example": "I want to travel to Europe one day!"}}"""
}, {
"input": "Can you tell me the meaning of bright?",
"output": """{{"definition": "Bright means that there is a lot of light in an area", "synonym": "well-lit", "antonym": "dark", "example": "The room is bright in the afternoon"}}"""
}
]In this article, we’re just going to build a big function. So let’s put all this together into a function we can run and get a response.
def get_vocab_from_llm(requested_word):
prefix = "The assistant is helping people to learn the English words that they have trouble with and want to know about. The assistant provides a simple explanation in English to define words, but also provides example words and phrases in English. The assistant must provide its response in properly formatted JSON. The following examples demonstrate the appropriate type of responses the assistant should provide to answer a user's query."
examples = [
{
"input": "What does travel mean?",
"output": """{{"definition": "Travel means to go to another place", "synonym": "venture", "antonym": "stay", "example": "I want to travel to Europe one day!"}}"""
}, {
"input": "Can you tell me the meaning of bright?",
"output": """{{"definition": "Bright means that there is a lot of light in an area", "synonym": "well-lit", "antonym": "dark", "example": "The room is bright in the afternoon"}}"""
}
]
vocab_llm_call = LLMBaseClass(prefix, examples)
output = vocab_llm_call.call_llm(input=f"What does {requested_word} mean?")
return outputLet’s try it out!
User: What does smile mean?
AI: ' {"definition": "Smile means to show happiness with your face by curving
your lips", "synonym": "grin", "antonym": "frown", "example": "She smiled
when she saw her friends"}'That looks pretty good. The output has all the keys we wanted - definition, synonym, antonym, and example. It is providing sentences or words appropriately. But it’s not JSON. It’s a string. You can tell because of the single quotes wrapping the object. We’ll need to try to convert that output to JSON. That’s not too hard…
import json
result = json.loads(ouput)…unfortunately, we can’t trust that we’ll always get a valid JSON object. We’re going to need to have some error handling to catch malformed responses. If we do catch one, we’ll just make it a blank dictionary.
import json
from json import JSONDecodeError
try:
result = json.loads(output)
except JSONDecodeError:
result = {}This is what we have so far.
def get_vocab_from_llm(requested_word):
prefix = "The assistant is helping people to learn the English words that they have trouble with and want to know about. The assistant provides a simple explanation in English to define words, but also provides example words and phrases in English. The assistant must provide its response in properly formatted JSON. The following examples demonstrate the appropriate type of responses the assistant should provide to answer a user's query."
examples = [
{
"input": "What does travel mean?",
"output": """{{"definition": "Travel means to go to another place", "synonym": "venture", "antonym": "stay", "example": "I want to travel to Europe one day!"}}"""
}, {
"input": "Can you tell me the meaning of bright?",
"output": """{{"definition": "Bright means that there is a lot of light in an area", "synonym": "well-lit", "antonym": "dark", "example": "The room is bright in the afternoon"}}"""
}
]
vocab_llm_call = LLMBaseClass(prefix, examples)
output = vocab_llm_call.call_llm(input=f"What does {requested_word} mean")
try:
result = json.loads(output)
except JSONDecodeError:
result = {}
return resultWe have our basic LLM call set up! Test it out!
User: What does scale up mean
AI: {'definition': 'Scale up means to increase in size or amount',
'synonym': 'expand',
'antonym': 'shrink',
'example': 'We need to scale up our production to meet the demand'}Now, we’re going to need to integrate our database calls into the function. So we need to get our database set up. We’ll use Supabase for now. Create an account if you don’t already have one.
Click "New project"

In the pop up, click "New organization"

Give your “organization” a name. Click "Create organization."

Fill out the new form that appears. Click "Generate a password". Write down the password. In this article, we won’t actually make use of the password. However, once you leave the page, the password will be gone. If you forget it, you’ll have to recreate it if you want to use it Supabase later. Click "Create new project"

Copy your API key. Put it into your .env file.

Click the table icon.

Click "New table".

Disable "Enable Row Level Security (RLS)"

Give table a name - vocab. Then, add the columns that we need. Supabase has already created id and created_at for us. The LLM is giving us the definition, synonym, antonym, and example. So we need fields for those. We also need to save the user’s request, which we can call “word”. We also should save the raw string the LLM provided. If the json.loads() is successful, we can also save the converted output as “llm_output”.
Notice that almost every field has a default value of NULL. In order for the function to work, we need a “word” from the user and the LLM should output something. If the LLM’s response is malformed, though, we may not have any of the other fields besides “word” and “raw_llm_output” (and '“id” and “created_at” since Supabase autogenerates them). Once you have set up your database like below, click “Save.”
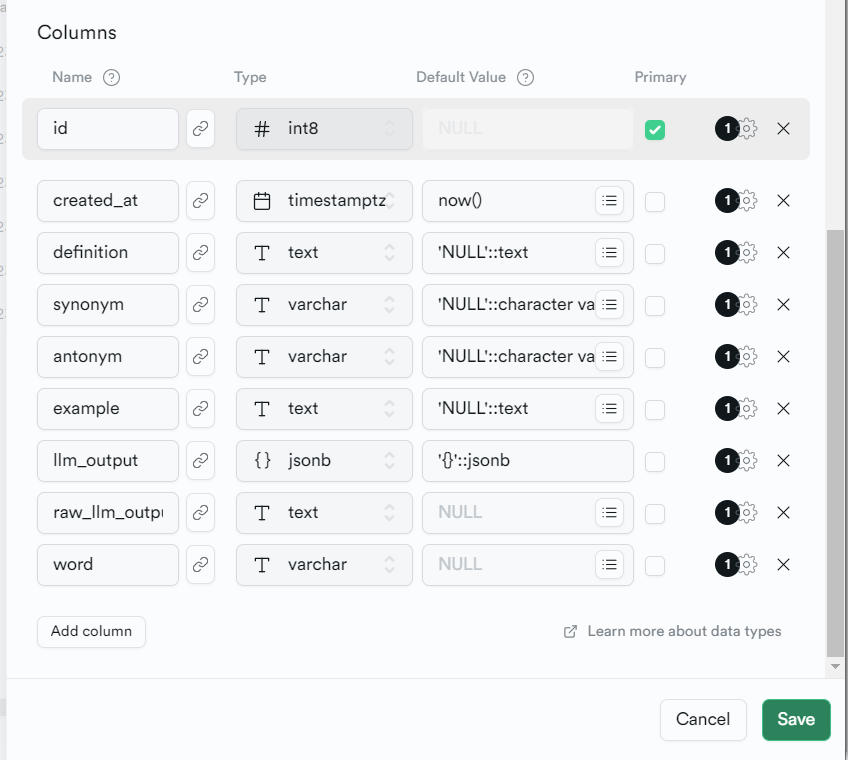
Now, we need to get our information. Click on the gear icon.

Click on “API”.
You will see the URL for your Supabase instance. Copy that, and put it in your .env file.

Let’s use the database now! We’ll start by setting up Supabase.
pip install supabaseWe’ll import the stuff we need from supabase and set up our client. This will allow us to interact with Supabase. Make sure you have put the URL and API key in your .env file.
import supabase
from supabase import create_client, Client
import os
url = os.environ.get('SUPABASE_URL')
key = os.environ.get('SUPABASE_API_KEY')
supabase: Client = create_client(url, key)Let’s start with the save call first. Supabase’s insert takes a dictionary. Luckily the LLM sent us a nicely formatted JSON object - “result”. This will fill in the columns for definition, synonym, antonym, and example. However, for the other columns, we will extend the “result” object with |. | is concise Python 3.9 syntax that allows you to combine two dictionaries. The second dictionary contains all the other values we want to record.
Unfortunately, we may not always get a nicely formatted JSON object. It may be malformed. We’ll need to handle that case, too. The following line should also work in that case because we return an empty dictionary if the json.loads fails.
supabase.table('vocab').insert(result | {"llm_output": result, "raw_llm_output": output, "word": requested_word}).execute()At the beginning of our function, we can check whether we have already recorded an entry for a word. This can help speed up the function because we don’t have to spend time with the LLM if we don’t need it. We also don’t have to pay for unnecessary calls.
result = supabase.table('vocab').select('*').eq('word', requested_word).execute()
if result.data:
return result.dataOur function looks like this now.
import json
import os
import supabase
from json import JSONDecodeError
from langchain import OpenAI, ConversationChain, LLMChain, PromptTemplate, FewShotPromptTemplate
from langchain.memory import ConversationBufferMemory
from supabase import create_client, Client
url = os.environ.get('SUPABASE_URL')
key = os.environ.get('SUPABASE_API_KEY')
supabase: Client = create_client(url, key)
class LLMBaseClass():
suffix = """
Current conversation:
{history}
User: {input}
AI: """
example_template = """
Example
User: {input}
AI: {output}
"""
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template=example_template
)
def __init__(
self,
prefix,
examples,
suffix=suffix,
example_template=example_template,
example_prompt=example_prompt,
):
self.prefix=prefix
self.suffix=suffix
self.example_template=example_template
self.example_prompt=example_prompt
self.examples=examples
def create_few_shot_prompt_template(self):
return FewShotPromptTemplate(
prefix=self.prefix,
suffix=self.suffix,
examples=self.examples,
example_prompt=self.example_prompt,
input_variables=["history", "input"],
example_separator="\n\n"
)
def call_llm(self, input):
language_bot_chain = LLMChain(
llm=OpenAI(temperature=0),
prompt=self.create_few_shot_prompt_template(),
verbose=True,
memory=ConversationBufferMemory(),
)
output = language_bot_chain.predict(input=input)
return output
def get_vocab_from_llm(requested_word):
result = supabase.table('vocab').select('*').eq('word', requested_word).execute()
if result.data:
return result.data
prefix = "The assistant is helping people to learn the English words that they have trouble with and want to know about. The assistant provides a simple explanation in English to define words, but also provides example words and phrases in English. The assistant must provide its response in properly formatted JSON. The following examples demonstrate the appropriate type of responses the assistant should provide to answer a user's query."
examples = [
{
"input": "What does travel mean?",
"output": """{{"definition": "Travel means to go to another place", "synonym": "venture", "antonym": "stay", "example": "I want to travel to Europe one day!"}}"""
}, {
"input": "Can you tell me the meaning of bright?",
"output": """{{"definition": "Bright means that there is a lot of light in an area", "synonym": "well-lit", "antonym": "dark", "example": "The room is bright in the afternoon"}}"""
}
]
vocab_llm_call = LLMBaseClass(prefix, examples)
output = vocab_llm_call.call_llm(input=f"What does {requested_word} mean")
try:
result = json.loads(output)
except JSONDecodeError:
result = {}
supabase.table('vocab').insert(result | {"llm_output": result, "raw_llm_output": output, "word": requested_word}).execute()
return resultThis function isn’t perfect. It’s slow with multiple database calls and an LLM call. Also, this function is only getting information about one word. We could rework this function and the LLM prompt to work with a larger batch of words. We may run this function while the system is preparing a cohesive set of activities, such as a reading and an info gap activity.
LLMs can be a great resource for a lot of tasks, but we don’t need to call on them to repeat what they’ve already done. Persisting the responses may reduce the cost of using an LLM. More importantly, though, it can give you more opportunity to proactively review those responses to understand if your prompts are working, if the LLM is producing misinformation, and if you can get more insights about your users.