Local, offline chatting with LibreChat and Ollama
The conversational AI landscape is full of ways to connect to LLMs. Each LLM provider offers its own chat interface and API endpoints for interacting with their models. Services like OpenRouter offer access to many LLM models via a standardized API. When using these online services, you need to send your data to external systems, where you may not have much control over what’s done with your data. LibreChat and Ollama can help you interact with LLM models offline.
LibreChat is a feature-rich, customizable chat platform. You can generally select the model sources that you want to use, whether provider-specific APIs or your own local models. Additionally, it offers things like multi-modal chats, saving preset model configurations, RAG on your local documents, and even password-protected user accounts.
Ollama offers a way to manage and run LLM models locally. While it lacks some popular proprietary models, it still has powerful models like llama 3 and gemma 2. Often, it offers these at different sizes like 8B or 70B so that you can choose one appropriate for your machine.
We will run both of these applications through Docker. LibreChat recommends building from Docker. In the case of Ollama, some people don’t like how it works on one’s machine. These concerns may have been addressed. Nonetheless, we’ll look at two different ways to use it.
Ollama setup
Option 1: Local installation
If you want an easier set up, you can install Ollama by visiting their download page and selecting the appropriate method for your operating system. You can run that and then skip down passed the Docker steps.
Note: If you have trouble connecting to Ollama from LibreChat, you may need to update the ollama.service file (Git issue). You can add the following line. On my linux machine, this was at /etc/systemd/system, but it may be elsewhere for you.
Environment="OLLAMA_HOST=0.0.0.0:11434"Option 2: Docker container installation
Ollama provides an official Docker image that you can use to run the application. They have different instructions for using the service with CPU only or with GPU. The command on the DockerHub page seems to save the models within the Docker container, which is fine. However, you can have the files on your local disk outside of the Docker container if your prefer.
# Saves files to the container
docker run -d -v ollama:/root/.ollama ./ollama-models -p 11434:11434 --name ollama ollama/ollama
# Saves files to local folder
docker run -d -v $(pwd)/ollama_data:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaOne interesting point to note is that the “-v ollama:/root/.ollama” will allow that Docker container to save the model files directly to your computer within the directory you are working in.
LibreChat actually offers settings to create this Docker container. However, you may want to use Ollama with other projects. In that case, having a separate Ollama folder that contains the models may make more sense. Additionally, you can start Ollama up and close it down independently of LibreChat. I’ll leave where you run the Ollama Docker container up to you, but the remainder of the article will assume you did not make use of LibreChat to build the Docker container.
Now that you have Ollama installed, you need to download a model to use. Ollama offers a number of models. For our purposes, let’s use the very small tinydolphin model to test out our set up.
Note that if you used the Docker container installation, you will need to prepend the commands below with “docker exec -it ollama” to execute the command within the Docker container as shown in the next code block. Note that the “ollama” after “-it” refers to the Docker container and next “ollama” is calling the service’s command line. Both are necessary.
# Local installation
>>> ollama pull tinydolphin
# Docker container installation
>>> docker exec -it ollama ollama pull tinydolphinCheck to make sure that the model has downloaded to your computer successfully.
>>> ollama ls
NAME ID SIZE MODIFIED
tinydolphin:latest 0f9dd11f824c 636 MB 1 minute agoYou can also view information about the model, such as its parameters and context length.
>>> ollama show tinydolphinYou can test that ollama is working by sending it a request.
>>> import requests, json
>>> resp = requests.post("http://localhost:11434/v1/chat/completions", headers={"Content-Type": "application/json"}, data=json.dumps({"messages": [{"role":"user", "content":"Hello, how are you?"}], "model": "tinydolphin"})).json()
{'id': 'chatcmpl-101',
'object': 'chat.completion',
'created': 1724511803,
'model': 'tinydolphin',
'system_fingerprint': 'fp_ollama',
'choices': [{'index': 0,
'message': {'role': 'assistant',
'content': "Hi! I'm glad to hear you're doing well. How can I help you today?"},
'finish_reason': 'stop'}],
'usage': {'prompt_tokens': 35, 'completion_tokens': 22, 'total_tokens': 57}}LibreChat set up
With the model ready, you need to download the LibreChat repository.
git clone https://github.com/danny-avila/LibreChatMove into the LibreChat folder.
cd LibreChatLibreChat provides template files to help you adjust how the platform works. For example, it has settings for adding an “ollama service”, which is basically the Docker container we spun up earlier. It offers other things like monitoring and caching. These files let you tailor the LibreChat-related Docker containers to include what you need.
First, you need to copy over the environment variables. We actually won’t make any changes to this file, but it needs to be present for the application to build correctly.
cp .env.example .envNext, you need to create librechat.yaml. You could copy this from the .example version. However, it can get confusing to uncomment random lines around the file. Instead create the empty file manually.
>>> nano librechat.yamlThen, copy the following into the file. We need to make adjustments to the Ollama section. We are specifying what models are available and the URL where LibreChat can reach Ollama. Then, CTRL+X to save.
# For more information, see the Configuration Guide:
# https://www.librechat.ai/docs/configuration/librechat_yaml
# Configuration version (required)
version: 1.1.5
# Cache settings: Set to true to enable caching
cache: true
# Custom interface configuration
interface:
# Privacy policy settings
privacyPolicy:
externalUrl: "https://librechat.ai/privacy-policy"
openNewTab: true
# Terms of service
termsOfService:
externalUrl: "https://librechat.ai/tos"
openNewTab: true
# Example Registration Object Structure (optional)
registration:
socialLogins: ["github", "google", "discord", "openid", "facebook"]
# Definition of custom endpoints
endpoints:
custom:
- name: "Ollama"
apiKey: "ollama"
baseURL: "http://host.docker.internal:11434/v1/"
models:
default:
[
"tinydolphin:latest",
]
fetch: false
titleConvo: true
titleModel: "current_model"
summarize: false
summaryModel: "current_model"
forcePrompt: false
modelDisplayLabel: "Ollama"Next, you need to create docker-compose.override.yaml. Again, make an empty file.
>>> nano docker-compose.override.yamlAdd the following to the file. Then, CTRL+X to save.
version: '3.4'
services:
api:
volumes:
- type: bind
source: ./librechat.yaml
target: /app/librechat.yamlWith that set up done, start LibreChat.
docker compose upUsing LibreChat
LibreChat will be available at localhost:3080. Create an account, and log in.
The LibreChat screen will default to OpenAI. However, you would need to add a key for that option to work. Since we’re focused on Ollama, select that from the menu. Then, make sure tinydolphin is available and selected.
You can type a message in and tinydolphin will respond from your local machine.
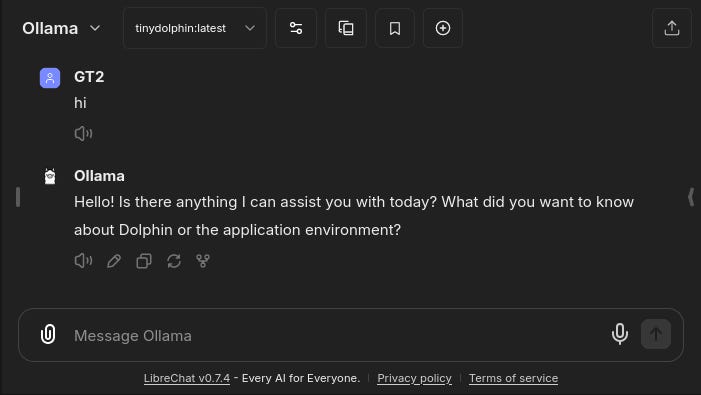
Tinydolphin may not be as powerful as more recent models, but it is a great model for simple testing and quick responses. It doesn’t take up much space. However, you may want to use a more advanced model. To do so, you need to follow the steps from earlier.
First, pull a new model from Ollama, like gemma:2b.
docker exec -it ollama ollama pull gemma:2bThen, update your librachat.yaml to include the new model.
models:
default:
[
"tinydolphin:latest",
"gemma:2b"
]You need to restart your docker containers.
docker compose restartWhen you finish your chat session, you can shut down LibreChat. Your data will still remain in the LibreChat folder.
docker compose downOllama and LibreChat are powerful tools for facilitating conversational experiences. Ollama provides a way to run models locally. This can minimize costs of testing chats, and it can keep your data on your system. You can run the models offline so spotty internet at the cafe won’t stop you!
LibreChat offers a power platform with features that allow you to customize your chat experience. Quality of life features like chat search, forking conversations, bookmarks, and LLM setting presets all help enrich how you interact with your chats. It offers many other powerful features like voice, web search, and image generation, though these send data outside your machine.